Regex - 学习正则
正则表达式
概念
正则表达式,又称规则表达式,通常缩写成“regex”,单数有regexp、regex,复数有regexps、regexes、regexen。正则表达式概念源于Unix中的sed、grep等文本编辑软件。在计算机科学中,是指一个用来描述或者匹配一系列符合某个句法规则的字符串的单个字符串。正则表达式通常被用来检索和/或替换那些符合某个模式的文本内容。
正则的来源
1956年:一位名叫Stephen Kleene的数学科学家发表了一篇题目是《神经网事件的表示法》的论文,利用称之为正则集合的数学符号来描述此模型,引入了正则表达式的概念。正则表达式被作为用来描述其称之为“正则集的代数”的一种表达式,因而采用了“正则表达式”这个术语。 1968年:C语言之父、UNIX之父肯·汤普森把这个“正则表达式”的理论成果用于做一些搜索算法的研究,他描述了一种正则表达式的编译器,于是出现了应该算是最早的正则表达式的编译器qed(这也就成为后来的grep编辑器)。 Unix使用正则之后,正则表达式不断的发展壮大,然后大规模应用于各种领域,根据这些领域各自的条件需要,又发展出了许多版本的正则表达式,出现了许多的分支。我们把这些分支叫做“流派”。 1987年:Perl语言诞生了,它综合了其他的语言,用正则表达式作为基础,开创了一个新的流派,Perl流派。之后很多编程语言如:Python、Java、Ruby、.Net、PHP等等在设计正则式支持的时候都参考Perl正则表达式。
20世纪40年代:正则表达式最初的想法来自两位神经学家:沃尔特·皮茨与麦卡洛克,他们研究出了一种用数学方式来描述神经网络的模型。语法 & 常见的正则表达式
语法
正则表达式由两种基本字符类型组成:
普通文本字符和元字符。普通字符包括大小写的字母和数字,而元字符则具有特殊的含义。下面引用了知乎帖子上大神整理的 正则表达式 的符号用法。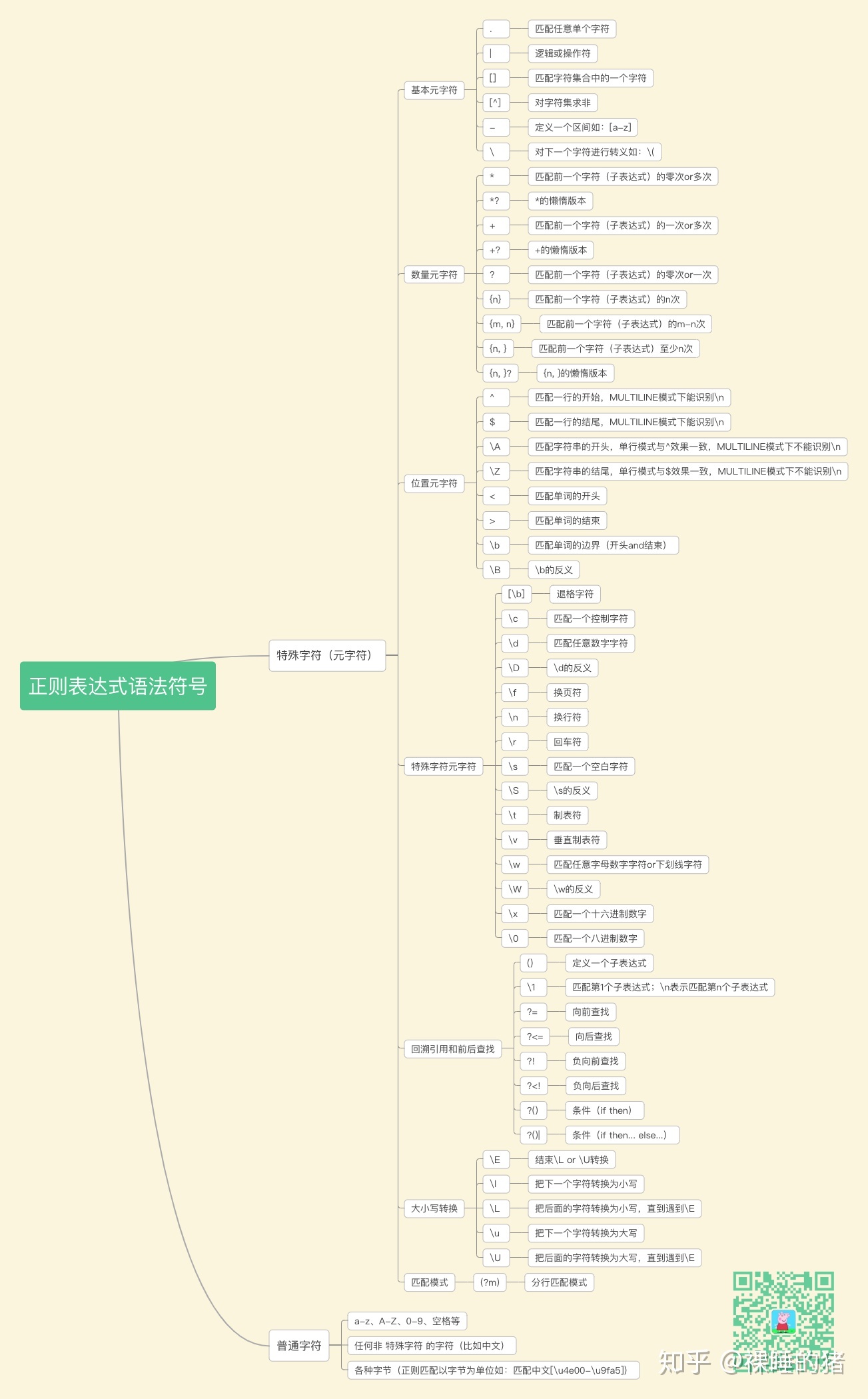
普通字符:最简单的正则表达式是与搜索字符串相比较的单个普通字符。 例如,单字符正则表达式 A 会始终匹配字母 A,无论其会出现在搜索字符串的哪个位置。
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符。 这包括所有大小写字母、所有数字、所有标点符号和一些符号。元字符: 除普通字符之外,正则表达式还可以包含“元字符”(有魔法)。 例如,元字符 \d,它与数字字符相匹配。
匹配任意字符: 句点 (.) 可匹配字符串中的任意单个打印或非打印字符,换行符 (\n) 除外。 /a.c/ 正则表达式可匹配“aac”、“abc”、“acc”、“adc”、“a1c”、“a2c”、“a-c”和“a#c”。
然而若要匹配搜索字符串中包含的句点 (.),则可以在表达式中句点的前面放置一个反斜杠 ()匹配字符列表: 可以通过在方括号 [ ] 中放置一个或多个单个字符,创建匹配字符的列表。括号表达式中的任何字符均仅与正则表达式中紧邻括号表达式的单个字符相匹配。 例如,/Chapter [12345]/ 表达式匹配“Chapter 1”、“Chapter 2”、“Chapter 3”、“Chapter 4”和“Chapter 5”。
要使用范围代替字符本身来表示匹配字符,可以使用连字符 (-)。 表达式 /Chapter [1-5]/ 与 /Chapter [12345]/ 等效。
若要查找不在列表或范围内的所有字符,请将插入符号 (^) 放在列表的开头。 例如,表达式 /[^aAeEiIoOuU]/ 匹配任何非元音字符。
限定符: 可以使用“限定符”指定其中的单个字符或字符集重复指定次数的正则表达式。限定符引用在其前面并与其紧邻(左侧)的表达式。
限定符位于大括号 {} 中,并包含指示出现次数上下限的数值。 例如,c{1,2} 匹配 1 个或 2 个字母 c。
仅指定一个数字时,除非其后紧跟一个逗号,否则表示上限。 例如,c{3} 匹配 3 个字符 c,而 c{5,} 匹配 5 个或更多字母 c。限定符 显式限定符 含义 * {0,} 匹配上一个元素零次或多次。 + {1,} 匹配上一个元素一次或多次。 ? {0,1} 匹配前面的元素零次或一次。 for example:
正则表达式 限定符的含义 匹配 /Chapter [1-9][0-9]{0,}/ 或/Chapter [1-9][0-9]*/ 匹配 [0-9] 零次或多次。 “Chapter 1”、“Chapter 25”、“Chapter 401320” /Chapter [0-9]{1,2}/ 匹配 [0-9] 一次或两次。 “Chapter 0”、“Chapter 03”、“Chapter 1”、“Chapter 25”、“Chapter 40” /Chapter [1-9][0-9]{0,1}/ 或/Chapter [1-9][0-9]?/ 匹配 [0-9] 零次或一次。 “Chapter 1”、“Chapter 25”、“Chapter 40” 或: “|”字符指定表示匹配的两个或多个替换项。 正则表达式 /(Chapter|Section) [1-9]/ 匹配以下内容:“Chapter 1”、“Chapter 9”和“Section 2”。
常见的正则表达式:
- 匹配中文字符的正则表达式: [\u4e00-\u9fa5] (在项目的代码中曾看到过)
- 匹配空白行的正则表达式:\n\s*\r
- 匹配Email地址的正则表达式:\w+([-+.]\w+)*@\w+([-.]\w+).\w+([-.]\w+)
- 匹配帐号是否合法(字母开头,允许6-16字节,允许字母数字下划线):^[a-zA-Z][a-zA-Z0-9_]{5,15}$ (在项目的代码中曾看到过)
- 匹配网址URL的正则表达式:[a-zA-z]+://[^\s]*
- 匹配ip地址:\d+.\d+.\d+.\d+
- 匹配特定数字:
1
2
3
4
5
6
7^[1-9]\d*$ //匹配正整数
^-[1-9]\d*$ //匹配负整数
^-?[1-9]\d*$ //匹配整数
^[1-9]\d*|0$ //匹配非负整数(正整数 + 0)
^-[1-9]\d*|0$ //匹配非正整数(负整数 + 0)
^[1-9]\d*\.\d*|0\.\d*[1-9]\d*$ //匹配正浮点数
^-([1-9]\d*\.\d*|0\.\d*[1-9]\d*)$ //匹配负浮点数 - 匹配特定字符串:
1
2
3
4
5^[A-Za-z]+$ //匹配由26个英文字母组成的字符串
^[A-Z]+$ //匹配由26个英文字母的大写组成的字符串
^[a-z]+$ //匹配由26个英文字母的小写组成的字符串
^[A-Za-z0-9]+$ //匹配由数字和26个英文字母组成的字符串
^\w+$ //匹配由数字、26个英文字母或者下划线组成的字符串
正则表达式的原理&底层的了解
因为正则表达式是由正则表达引擎编译执行,所以需要了解引擎的运行过程。如 下图 所示
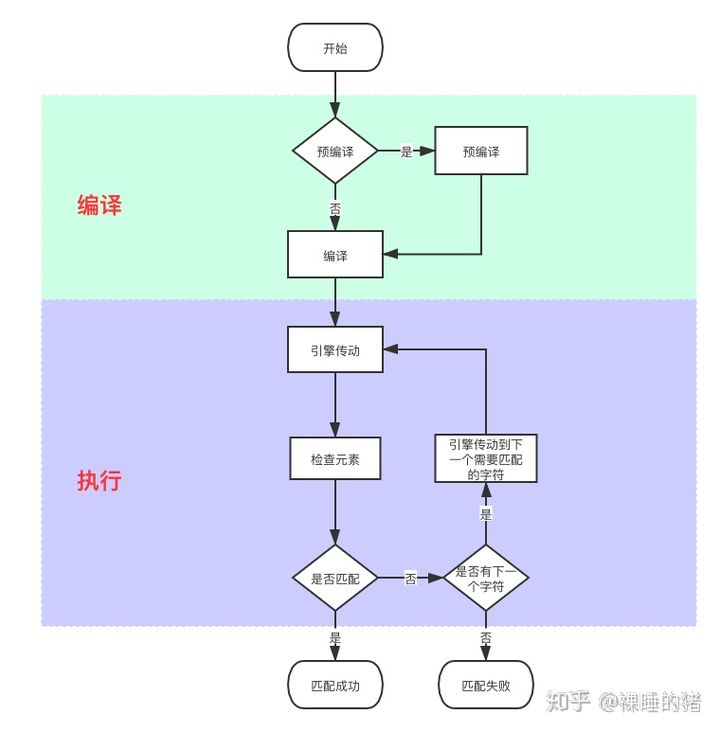
预编译: 看到流程图中有分支选择是否预编译,据了解,预编译的执行速度会比即时搜索快。体现在java代码中就是1
2
3
4
5//先预编译
private final java.util.regex.Pattern p1 = java.util.regex.Pattern.compile("[!@#$%^&*()_+\\-=/;',.:\"<>?\\\\]");
//后查询
int count = (p1.matcher(req.getLoginPwd()).find() ? 1 : 0) + (p2.matcher(req.getLoginPwd()).find() ? 1 : 0)
+ (p3.matcher(req.getLoginPwd()).find() ? 1 : 0);引擎:
正则引擎主要可以分为基本不同的两大类:DFA (Deterministic finite automaton) 确定型有穷自动机
NFA (Non-deterministic finite automaton) 非确定型有穷自动机
还有一种引擎为:POSIX NFA,这是根据NFA引擎出的规范版本,但因为使用较少所以我们这里也就不重点讲解。
这里需要和大家解释下何为确定型、有穷、自动机这几个名词:
确定型与非确定型:假设有一个字符串(text=abc)需要匹配,在没有编写正则表达式的前提下,就直接可以确定字符匹配顺序的就是确定型,不能确定字符匹配顺序的则为非确定型。
有穷:有穷即表示有限的意思,这里表示有限次数内能得到结果。
自动机:自动机便是自动完成,在我们设置好匹配规则后由引擎自动完成,不需要人为干预!
根据上面的解释我们可得知DFA引擎 和 NFA引擎 的区别就在于:在没有编写正则表达式的前提下,是否能确定字符执行顺序!
回溯:当某个正则分支匹配不成功之后,文本的位置需要回退,然后换另一个分支匹配,而回退这步专业术语就叫:回溯。**但隐藏着回溯陷阱的风险,详情看 链接 **
回溯机制不但需要重新计算正则表达式和文本的对应位置,也需要维护括号内的子表达式所匹配文本的状态(b匹配成功),保存到内存中以数字编号的组中,这就叫捕获组。DFA引擎的一些特点:
- 文本主导:按照文本的顺序执行,这也就能说明为什么DFA引擎是确定型(deterministic)了,稳定!
- 记录当前有效的所有可能:当执行到
(d|b)时,同时比较表达式中的d和b,所以会需要更多的内存。 - 每个字符只检查一次:这提高了执行效率,而且速度与正则表达式无关。
- 不能使用反向引用等功能:因为每个字符只检查一次,文本零宽度(位置)只记录当前比较值,所以不能使用反向引用、环视等一些功能!
NFA引擎的一些特点:
- 文表达式主导:按照表达式的一部分执行,如果不匹配换其他部分继续匹配,直到表达式匹配完成。
- 会记录某个位置:当执行到
(d|b)时,NFA引擎会记录字符的位置(零宽度),然后选择其中一个先匹配。 - 单个字符可能检查多次:当执行到
(d|b)时,比较d后发现不匹配,于是NFA引擎换表达式的另一个分支b,同时文本位置回退,重新匹配字符’b’。这也是NFA引擎是非确定型的原因,同时带来另一个问题效率可能没有DFA引擎高。 - 可实现反向引用等功能:因为具有回退这一步,所以可以很容易的实现反向引用、环视等一些功能!
绝大多数的编程语言都采用的是NFA引擎,而NFA引擎的特点是:功能强大、但有回溯机制所以效率慢。所以我们需要学习一些NFA引擎的一些优化技巧,以减少引擎回溯次数以及更直接的匹配到结果!
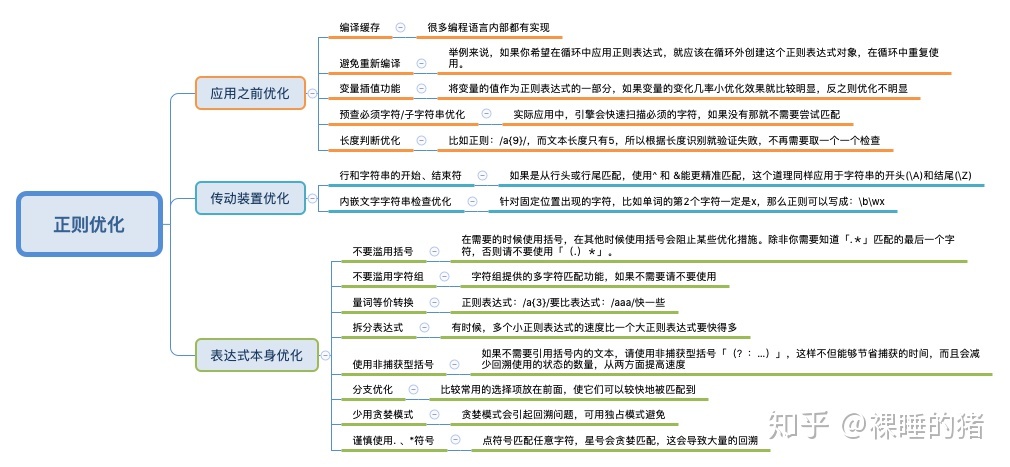
自己的一些启发
- 据了解,mysql也是可以在代码行中使用正则表达式,而直接在mysql执行正则搜索,和取出来在后端再进行正则。哪个效率更好呢?有机会我想做个测试~
推荐的网站
- fas fa-star 正则表达式常用字段/测试器
推荐书目